用python实现调用jar包
发布时间:2019-09-15 10:02:34编辑:auto阅读(2449)
本文作者:botoo
背景:python3.6 32位 + jre 32位 + windows64位
首先环境搭建:
安装jpype,安装的时候输入 pip install jpype1 (后面要加一个1)
*一定要注意 jre和python的位数一定要一样的
安装jre 根据你的python版本选择对应位数的jre文件http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
我下载的是:jre-8u151-windows-i586.tar.gz 下载后直接解压到本地d盘
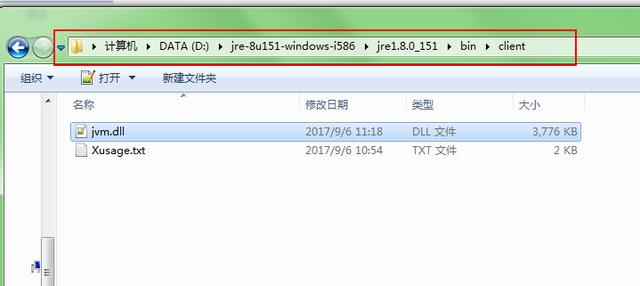
需要的是这个路径下的这个文件:
import jpype
# jvmPath = jpype.getDefaultJVMPath() jvmPath = ur'D:\jre-8u151-windows-i586\jre1.8.0_151\bin\client\jvm.dll'jpype.startJVM(jvmPath)
jpype.java.lang.System.out.println("hello world!")
jpype.shutdownJVM()执行不报错就成功。
下载完jar包,然后写py文件:
# -*- coding:utf-8 -*-
# Filename: main.py
# Author:hankcs
from jpype import *
import jpype
a=u'D:\\jre-8u151-windows-i586\\jre1.8.0_151\\bin\\client\\jvm.dll' #jvm.dll启动成功
jpype.startJVM(a, "-Djava.class.path=C:\\hanlp\\hanlp-portable-1.5.2.jar")
HanLP = JClass('com.hankcs.hanlp.HanLP')
# 中文分词
print(HanLP.segment('你好,欢迎在Python中调用HanLP的API'))
testCases = [
"商品和服务",
"结婚的和尚未结婚的确实在干扰分词啊",
"买水果然后来世博园最后去世博会",
"中国的首都是北京",
"欢迎新老师生前来就餐",
"工信×××干事每月经过下属科室都要亲×××代24×××换机等技术性器件的安装工作",
"随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。"]
for sentence in testCases: print(HanLP.segment(sentence))
# 命名实体识别与词性标注
NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer')
print(NLPTokenizer.segment('×××计算技术研究所的宗成庆教授正在教授自然语言处理课程'))
# 关键词提取
document = "水利部水资源司司长陈明忠9月29日在×××新闻办举行的新闻发布会上透露," \
"根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标," \
"有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,对一些取用水项目进行区域的限批," \
"严格地进行水资源论证和取水许可的批准。"
print(HanLP.extractKeyword(document, 2))
# 自动摘要
print(HanLP.extractSummary(document, 3))
# 依存句法分析
print(HanLP.parseDependency("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。"))
shutdownJVM()
运行结果如下:

上一篇: python 长连接 mysql数据库
下一篇: Python与Excel不得不说的事
- H3C基本命令大全
53138
- H3C IRF原理及 配置
40059
- Python exit()函数
34428
- python全系列官方中文文档
30177
- python 获取网卡实时流量
25082
- 1.常用turtle功能函数
24882
- python 获取Linux和Windows硬件信息
23268
- 天天基金网数据接口
16752
- Selenium使用代理IP&无头模式访问网站
14887
- Selenium&Pytesseract模拟登录+验证码识别
14386
- LangGraph Studio可视化
736°
- LangSmith开发-应用入门
685°
- LangGraph开发-多轮对话问答机器人
738°
- LangGraph开发-条件分支/循环图实战
761°
- LangGraph开发-生态介绍,入门demo实战
808°
- LangChain-接入12306-HTTP MCP智能体
937°
- LangChain接入自定义爬虫-MCP工具
908°
- LangChain接入Filesystem-MCP工具
924°
- LangChain搭建MCP服务端和客户端流程
1024°
- LangGraph与MCP技术概述
942°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
