1.概述
jupyter记事本是一个基于Web的前端,被分成单个的代码块或单元。根据需要,单元可以单独运行,也可以一次全部运行。这使得我们可以运行某个场景,看到输出结果,然后回到代码,根据输出结果对代码做出相应的调整(说白了就是可以直接在浏览器中编写Python程序,然后执行程序并输出结果,是不是感觉很方便呀!)。jupyter记事本对于数据探索是非常理想的选择。
2.安装
前提条件:Python环境已搭建好和pip已安装好(pip是 Python 包管理工具,该工具提供了对Python 包的查找、下载、安装、卸载的功能)。
2.1 安装IPython及IPython Notebook
1) pip install IPython
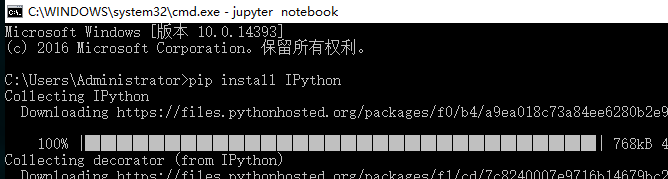
2) pip install urllib3 --安装IPython Notebook的依赖
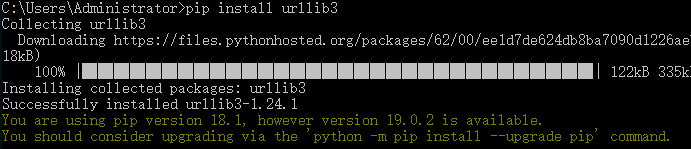
3) pip install jupyter --安装IPython Notebook
2.2 安装科学计算包
安装这些计算包是为了做数据分析
1) pip install numpy
2) pip install matplotlib
3) pip install pandas
4) pip install scipy
5) pip install scikit-learn
6) pip install seaborn
3.启动
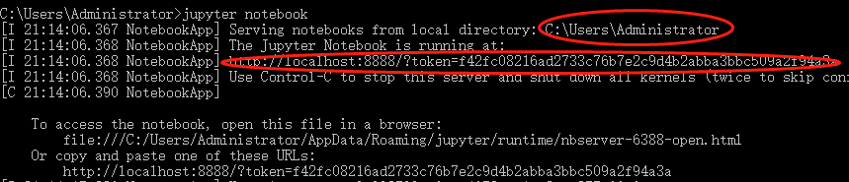
输入启动指令:jupyter notebook
我们可以在启动信息中看到存放记事本文件的本地路径还有Web应用地址
4.Demo
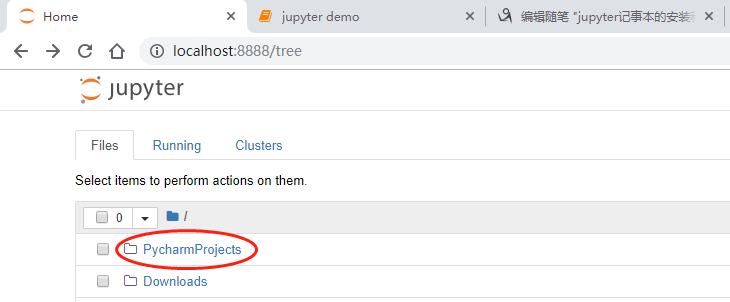
打开Web应用,然后我新建了一个名为PycharmProjects的文件夹
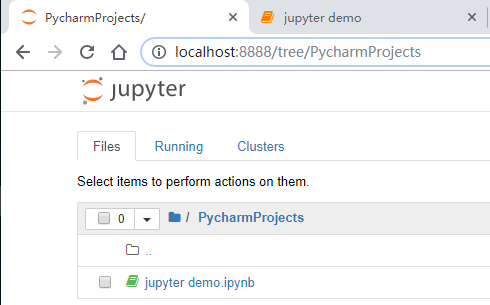
然后我在PycharmProjects的文件夹中新建了一个记事本,然后我们就可以通过记事本进行开发工作了。
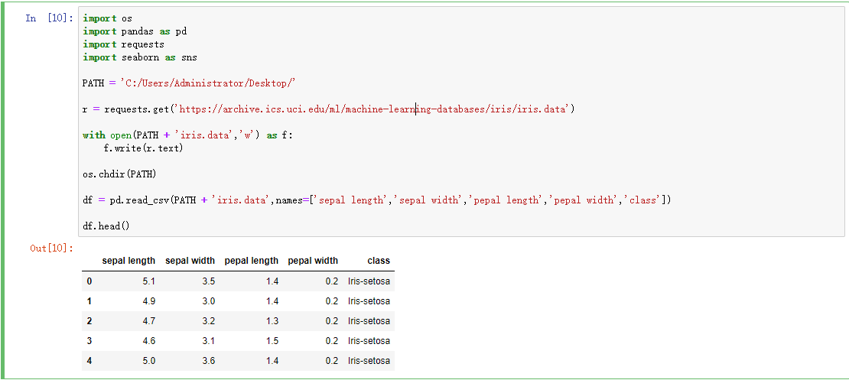
这里,我通过调用API接口的方式,获取到样例数据,并将该数据存放至本地文件,然后将文件中的数据输出至电子表格
import os import pandas as pd import requests import seaborn as sns PATH = 'C:/Users/Administrator/Desktop/' r = requests.get('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data') with open(PATH + 'iris.data','w') as f: f.write(r.text) os.chdir(PATH) df = pd.read_csv(PATH + 'iris.data',names=['sepal length','sepal width','pepal length','pepal width','class']) df.head()
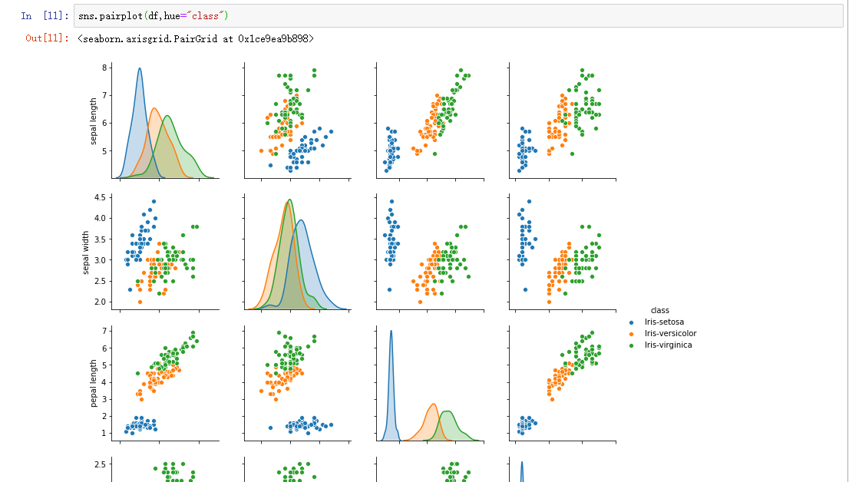
对数据做可视化操作
sns.pairplot(df,hue="class")