python中re time os sy
发布时间:2019-06-28 17:40:52编辑:auto阅读(2521)
- \d 是匹配一个数字
- \+ 大于等于1
- \w 匹配数字字母下划线和中横杠
- \* 匹配0个或多个
- \t 指标符
- . 除了回车意外的的所有
- * 大于等于0
- + 大于等于1
- ? 0或1
- {m},{m,n} 出现m次,出现m到n次,包括mn
re匹字符串
re.match()
- re.match(pattern, string, flags)
默认有3个参数,是最后一个我们不是很关注他,就默认。
通过你前面写的pattern(正则表达式的意思),匹配后面的string(字符串),他只能在你给的字符串的起始位置查找,注意和search的区别。
还有根据实践的结果,如果匹配失败返回nonere.search()
他和match有相同的作用,但是有区别。他会在整个字符串内容中匹配,直到找到第一个相匹配的字符串。
re.findall()
他和match和search差不多,但是他是找出字符串中所有的
import re result1 = re.match('\d+','dshfjasdsf23432dhfhsjdjfhjsd') if result1: print result1.group() result2 = re.search('\d+','dshfjasdsf23432dhfhsjdjfhjsd') print result2 print result2.group() result3 = re.findall('\d+','dshfjasdsf23432dhfhsjdjfhjsd34') print result3 #输出结果: <_sre.SRE_Match object at 0x0000000002BFA510> 23432 ['23432', '34']编译正则表达式
re.compile
他和编译生成的.pyc文件差不多,.pyc是为了再次使用时快速调用。正则表达式也可以经过编译,编译之后匹配其他的也会加快匹配速度
com = re.compile('\d+') print type(com) 输出结果: <type '_sre.SRE_Pattern'> 他返回了一个对象 - 使用方法:
也就是直接调用返回对象findall函数com = re.compile('\d+') print com.findall('dshfjasdsf23432dhfhsjdjfhjsd34') - 匹配一个文件中的所有字符串
- 匹配一个字符串中的ip
import re ip = 'sdhflsdhfj1723.234.234234.df.34.1234.df.324.xc.3+dsf172.25.254.1 sdfjk2130sdkjf.sdjfs' result1 = re.findall('(?:\d{1,3}\.){3}\d{1,3}',ip) result2 = re.findall('[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}',ip) print result1 print result2 #输出结果: ['172.25.254.1'] ['172.25.254.1']time 模块

时间的表示方式
- os.sep可以取代操作系统特定的路径分隔符。windows下为 “\”
- os.name字符串指示你正在使用的平台。比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'。
- os.getcwd()函数得到当前工作目录,即当前Python脚本工作的目录路径。
- os.getenv()获取一个环境变量,如果没有返回none
- os.putenv(key, value)设置一个环境变量值
- os.listdir(path)返回指定目录下的所有文件和目录名。
- os.remove(path)函数用来删除一个文件。
- os.system(command)函数用来运行shell命令。
- os.linesep字符串给出当前平台使用的行终止符。例如,Windows使用'\r\n',Linux使用'\n'而Mac使用'\r'。
- os.path.split(p)函数返回一个路径的目录名和文件名。
- os.path.isfile()和os.path.isdir()函数分别检验给出的路径是一个文件还是目录。
- os.path.existe()函数用来检验给出的路径是否真地存在
- os.curdir:返回当前目录('.')
- os.chdir(dirname):改变工作目录到dirname
- os.path.getsize(name):获得文件大小,如果name是目录返回0L
- os.path.abspath(name):获得绝对路径
- os.path.normpath(path):规范path字符串形式
- os.path.splitext():分离文件名与扩展名
- os.path.join(path,name):连接目录与文件名或目录
- os.path.basename(path):返回文件名
- os.path.dirname(path):返回文件路径
- os.stat() 相当于 Linux 下 stat 命令
- os.listdir() 列出给定目录的内容
- os.mkdir(path) 创建目录
- os.mkdirs(path) 创建目录树,相当于mkdir -p 操作
sys模块
- sys.argv 获取传递给脚本的参数,参数解析类似于 bash 的方式,第
一个参数代表脚本本身 - sys.exit(n) 退出程序,正常退出时exit(0)
- sys.version 获取Python解释程序的版本信息
- sys.maxint 最大的Int值
- sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
- sys.platform 返回操作系统平台名称
re模块
正则表达式
这里写反斜杠也是转义的意思,python在re模块中使用都需要加反斜杠
练习
import re
f = open('love.txt','r')
feitian = f.read()
f.close()
print re.findall('a',feitian)
##也可以一行一行的匹配
f = open("love.txt", "r")
while True:
line = f.readline()
if line:
line=line.strip()
p=line.rfind('.')
filename=line[0:p]
print line
else:
break
f.close()
输出:
['a', 'a', 'a']正则表达式中的分组
result2 = re.search('(\d+)\w*(\d+)','dshfjasdsf23432dhfhs23423jdjfhjsd')
print result2.group()
print result2.groups()
#输出结果:
23432dhfhs23423
('23432', '3')
#注意: 他不重复拿,这里解释一下为什么第二个输出为3,因为中间都被\w*接收了,这里我们在给一个例子
result2 = re.search('(\d+)dhfhs(\d+)','dshfjasdsf23432dhfhs23423jdjfhjsd')
print result2.group()
print result2.groups()
输出结果:
23432dhfhs23423
('23432', '23423')练习
import time
print time.time()
1510923748.06
#计算从1970年1月1日到现在有多少秒
print time.gmtime()
time.struct_time(tm_year=2017, tm_mon=11, tm_mday=17, tm_hour=13, tm_min=2, tm_sec=28, tm_wday=4, tm_yday=321, tm_isdst=0)
格式化成一个对象,他是当前的时间
print time.strftime('%Y%m%d')
20171117
输出格式化之后的时间,他的格式化和linux一样
他们之间的转换
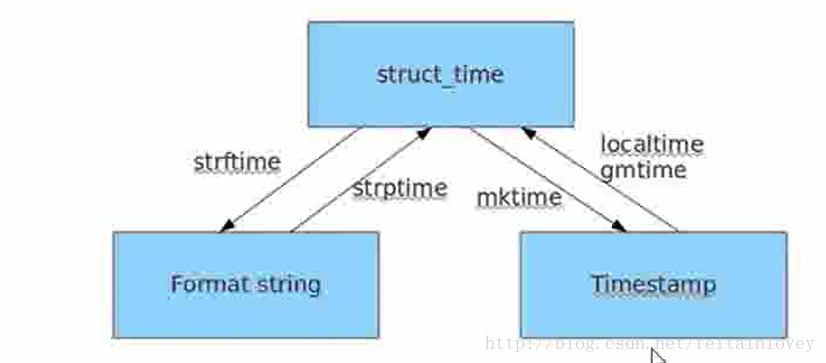
print time.strptime('2017-11-17','%Y-%m-%d')
time.struct_time(tm_year=2017, tm_mon=11, tm_mday=17, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=321, tm_isdst=-1)
#将字符串转化成结构化的时间格式
print time.localtime()
print time.mktime(time.localtime())
time.struct_time(tm_year=2017, tm_mon=11, tm_mday=17, tm_hour=21, tm_min=17, tm_sec=57, tm_wday=4, tm_yday=321, tm_isdst=0)
1510924677.0
#结构化的时间转化成时间戳的格式
#字符串格式的时间转时间戳格式他不能直接转,必须要中转
第一部分时间戳形式存在,第二部分以结构化形式存在,第三部分以字符串形式存在
os模块
上一篇: Python 正则表达式:split
下一篇: 每天一点点python----安装Pyt
- H3C基本命令大全
53086
- H3C IRF原理及 配置
40009
- Python exit()函数
34393
- python全系列官方中文文档
30143
- python 获取网卡实时流量
25041
- 1.常用turtle功能函数
24842
- python 获取Linux和Windows硬件信息
23217
- 天天基金网数据接口
16695
- Selenium使用代理IP&无头模式访问网站
14851
- Selenium&Pytesseract模拟登录+验证码识别
14346
- LangGraph Studio可视化
676°
- LangSmith开发-应用入门
635°
- LangGraph开发-多轮对话问答机器人
690°
- LangGraph开发-条件分支/循环图实战
714°
- LangGraph开发-生态介绍,入门demo实战
759°
- LangChain-接入12306-HTTP MCP智能体
889°
- LangChain接入自定义爬虫-MCP工具
854°
- LangChain接入Filesystem-MCP工具
873°
- LangChain搭建MCP服务端和客户端流程
970°
- LangGraph与MCP技术概述
890°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
