Python搭建博客网站小结
发布时间:2019-09-09 08:45:33编辑:auto阅读(3008)
- orm.py中实现元类 ModelMetaclass:创建一些特殊的类属性,用来完成类属性和表的映射关系,并定义一些默认的SQL语句,如SELECT, INSERT, UPDATE, DELETE等
- orm.py实现Model类:包含基本的getattr,setattr方法用于获取和设置实例属性的值,并实现相应的SQL处理函数,如find、findAll、save、remove等
- model.py中实现三个映射数据库表的类:User、Blog、Comment,在应用层用户只要使用这三个类即可
- coroweb.py中@get()装饰器给http请求添加请求方法和请求路径这两个属性;RequestHandler()调用url参数,将结果转换位web.response
- app.py中传入拦截器middlewares,通过add_routes()批量注册URL处理函数、init_jinja2()初始化jinja2模版、add_static()添加静态文件路径
- create_server()创建服务器监听线程
- 监听线程收到一个request请求
- 经过几个拦截器(middlewares)的处理(app.py中的app = web.Application..这条语句指定)
- 调用RequestHandler实例中的call方法;再调用call方法中的post或者get方法
- 调用handlers.py中响应的URL处理函数,并返回结果
- response_factory在拿到经URL处理函数返回过来的对象,经过一系列类型判断后,构造出正确web.Response对象,返回给客户端
引言
断断续续终于过了一遍廖雪峰的Python教程,于此梳理教程实战作业:搭建一个Blog网站。
由于欠缺前端知识,有些代码直接引用于项目源码,个人做了尽量详尽的注释以帮助理解,希望在今后能够学习HTML(HTML 30分钟入门教程)、CSS、JavaScript等知识,然后回头重新理解本项目。
作业托管于我的github
文件结构
awesome-python3-webapp/ <--根目录
|
+-www/ <--web项目目录
|
+-static/ <--静态资源目录
|
+-templates/ <--模板文件目录
| |
| +-__base__.html <--基础模版,父模版
| |
| +-blog.html <--文章详情模版,后加文章id构成完整路径
| |
| +-blogs.html <--首页模版
| |
| +-manage_blog_edit.html <--编辑文章模版
| |
| +-manage_blogs.html <--文章管理模版
| |
| +-manage_comments.html <--评论管理模版
| |
| +-manage_users.html <--用户管理模版
| |
| +-register.html <--注册模版
| |
| +-signin.html <--登陆模板
|
+-apis.py <--api接口,定义几个错误异常类和Page类用于分页
|
+-app.py <--HTTP服务器以及处理HTTP请求;拦截器、jinja2模板、URL处理函数注册等
|
+-config.py <--默认和自定义配置文件合并
|
+-config_default.py <--默认的配置文件信息
|
+-config_override.py <--自定义的配置文件信息
|
+-coroweb.py <--封装aiohttp,即写个装饰器更好的从Request对象获取参数和返回Response对象
|
+-favicon.ico <--网页缩略图标
|
+-handlers.py <--处理各种URL请求
|
+-markdown2.py <--支持markdown显示的插件
|
+-models.py <--采用ORM构建三个映射数据库表的类:User、Blog、Comment
|
+-models_test.py <--测试ORM
|
+-orm.py <--ORM框架
|
+-pymonitor.py <--用于支持自动检测代码改动重启服务
|
+-schema.sql <--创建表的SQL脚本关键技术
1.http工作流程
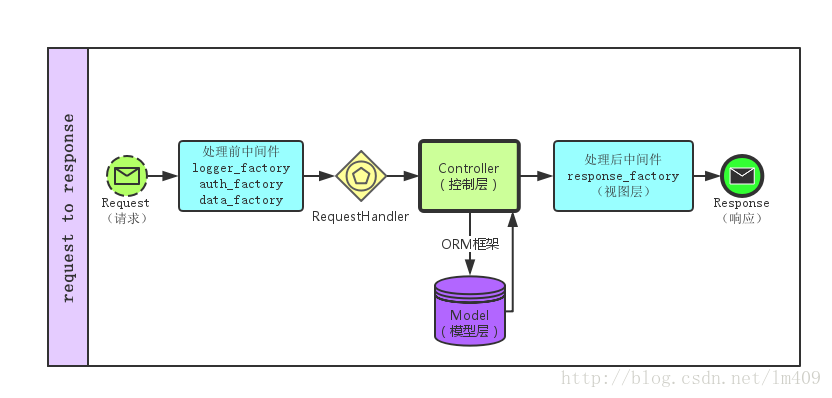
1. 客户端(浏览器)发起请求
2. 路由分发请求(这个框架自动帮处理),add_routes函数就是注册路由。
3. 中间件预处理
- 打印日志
- 验证用户登陆
- 收集Request(请求)的数据
4. RequestHandler清理参数并调用控制器(Django和Flask把这些处理请求的控制器称为view functions)
5. 控制器做相关的逻辑判断,有必要时通过ORM框架处理Model的事务。
6. 模型层的主要事务是数据库的查增改删。
7. 控制器再次接管控制权,返回相应的数据。
8. Response_factory根据控制器传过来的数据产生不同的响应。
9. 客户端(浏览器)接收到来自服务器的响应。
2.ORM框架Day3-Day4
ORM全称为对象关系映射(Object Relation Mapping),即用一个类来对应数据库中的一个表,一个对象来对应数据库中的一行,表现在代码中,即用类属性来对应一个表,用实例属性来对应数据库中的一行。具体步骤如下:
3.web框架Day5
aiohttp已经是一个Web框架了,在此主要对aiohttp库做更高层次的封装,从简单的WSGI接口到一个复杂的web framework,本质上还是对request请求对象和response响应对象的处理,可以将这个过程想象成工厂中的一条流水线生产产品,request对象就是流水线的原料,这个原料在经过一系列的加工后,生成一个response对象返回给浏览器。具体步骤如下:
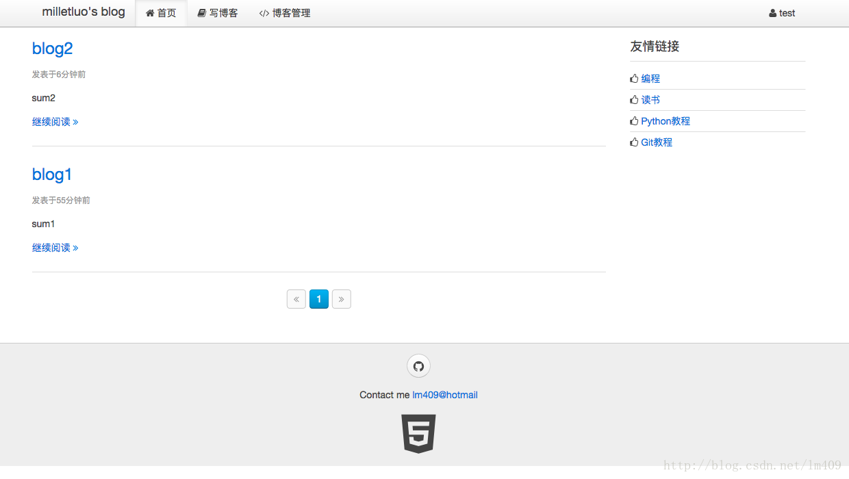
作业成果
博客首页:
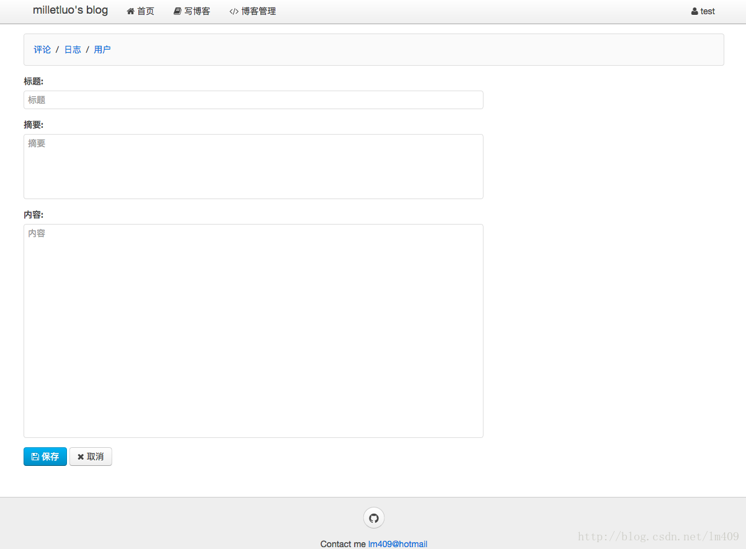
写博客:
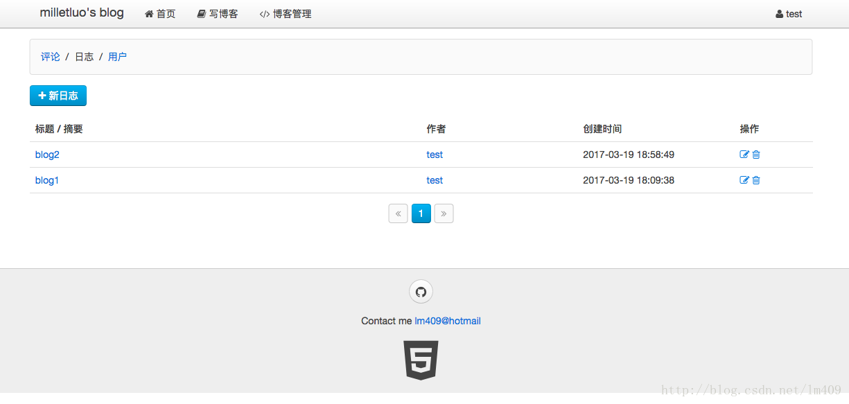
文章管理:
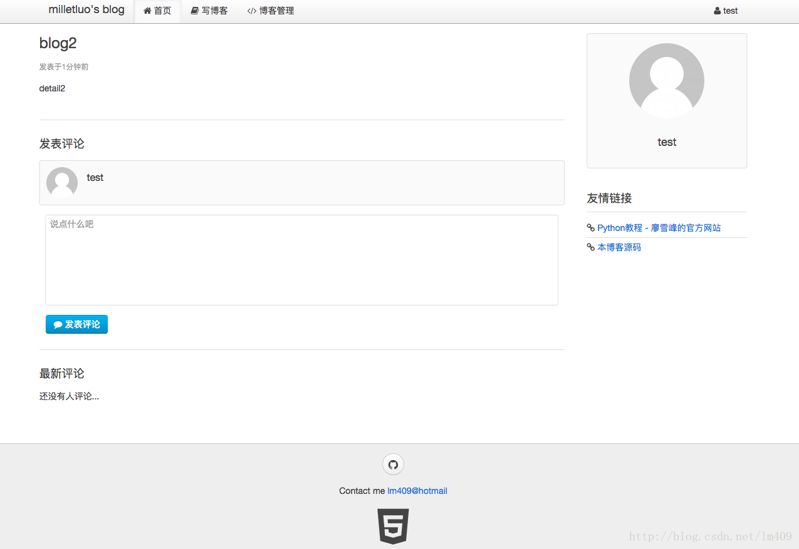
文章详情:
总结
通过该作业,基本了解了一个webapp的开发流程和部分技术,了解了http的工作原理,复习了python的使用。但是也深刻认识到python知识点的不熟练和前端相关知识的匮乏,后续仍要加强python项目练习和前端知识的学习。
参考
廖雪峰官网Blog网站实战
moling3650/mblog
zhouxinkai/awesome-python3-webapp
ReedSun/Preeminent
上一篇: [Python之道] 几种判断操作系统
下一篇: Python发送Http请求时,中文乱码
- H3C基本命令大全
53090
- H3C IRF原理及 配置
40015
- Python exit()函数
34396
- python全系列官方中文文档
30146
- python 获取网卡实时流量
25044
- 1.常用turtle功能函数
24844
- python 获取Linux和Windows硬件信息
23219
- 天天基金网数据接口
16697
- Selenium使用代理IP&无头模式访问网站
14853
- Selenium&Pytesseract模拟登录+验证码识别
14348
- LangGraph Studio可视化
681°
- LangSmith开发-应用入门
637°
- LangGraph开发-多轮对话问答机器人
694°
- LangGraph开发-条件分支/循环图实战
719°
- LangGraph开发-生态介绍,入门demo实战
763°
- LangChain-接入12306-HTTP MCP智能体
894°
- LangChain接入自定义爬虫-MCP工具
857°
- LangChain接入Filesystem-MCP工具
878°
- LangChain搭建MCP服务端和客户端流程
972°
- LangGraph与MCP技术概述
894°
- 姓名:Run
- 职业:谜
- 邮箱:383697894@qq.com
- 定位:上海 · 松江
