一、前言
关于Python的xlrd、xlwt模块的使用,推介另一位博客主的博文:https://www.cnblogs.com/zhoujie/p/python18.html
这篇里面有详细介绍这两个模块的基本用法。
以下是关于我运用xlrd、xlwt模块的一个实例。需求如下:

需求是用宏去做的,但是因为时间比较紧急,我用了1天去“研究”怎么用宏去写,发现作为一个VBA入门者,比较难短时间学习并解决这个问题,因为VBA的可读性比较差的缘故吧。
于是我选择用Python去实现。
二、主体
这个需求还算比较简单,主要是分为“读”和“写”两部分。
(一)读取部分
从Excel文件“测试题.xls”里面的“表格数据1”,“表格数据2”,“数据透视表”三个sheet中提取区域和各区域的店铺,并要求同一区域内的店铺名称不重复。
需求也很简单,就是“区域”和“店铺名称”两个元素进行去重和读取。
1.读取思路
1.1读取范围
读取范围主要是从“表格数据1”,“表格数据2”,“数据透视表”三个sheet中提取区域和各区域的店铺,如下:
三个表都是从A1,B1或者A2,B2开始,但是表的末尾有些其他文字注释,于是我用的判断条件设为是否中文和是否为空值。
#构造一个函数判断是否中文 def is_Chinese(word): for ch in word: if '\u4e00' <= ch <= '\u9fff': return True return False
1.2去重判断
读取到的数据需要一个临时的“容器”,打算利用单个区域和店铺放到一个元组里面,然后把所有的元组放到一个列表里面。
然后将每个新元组和列表里面的元组对比,看是否已经存在于列表中,从而达到去重的目的。
def read_excel(): # 打开文件 workbook = xlrd.open_workbook(r'D:\安装包\测试题.xls') #写一个循环体,筛选出不重复的区域和店铺 #将涉及到区域和店铺的三个sheet中,不重复的区域和店铺名称写入元组内并存于一个列表内 sheet_name = ['表格数据1','表格数据2','数据透视表'] tup1 = [] for j in range(3): sheet_source = workbook.sheet_by_name(sheet_name[j]) nrows = sheet_source.nrows for i in range(nrows): if is_Chinese(sheet_source.cell(i,0).value) == False and sheet_source.cell(i,0).value != "": a = (sheet_source.cell(i,0).value,sheet_source.cell(i,1).value) if a not in tup1 : tup1.append(a) else: pass else: pass
读取完数据,按照它的需求,是要弹出一个提示框的
#python弹出窗口,提示“读取完成!” msg.showinfo("Excel_Reading","读取已经完成!")
1.3统计店铺数量
“容器”tup1列表里面,放的是原始的数据,需要写个循环,去统计不同区域内的店铺数量。
#利用将元组转为字典,并统计各个区域的店铺数量 dict1 = {} for i in tup1: if i[0] not in dict1.keys(): dict1[i[0]] = 1 else: dict1[i[0]] += 1
读取部分完成。完整代码如下:
import xlrd import xlwt import tkinter.messagebox as msg def is_Chinese(word): for ch in word: if '\u4e00' <= ch <= '\u9fff': return True return False #读取数据 def read_excel(): # 打开文件 workbook = xlrd.open_workbook(r'D:\安装包\测试题.xls') #写一个循环体,筛选出不重复的区域和店铺 #将涉及到区域和店铺的三个sheet中,不重复的区域和店铺名称写入元组内并存于一个列表内 sheet_name = ['表格数据1','表格数据2','数据透视表'] tup1 = [] for j in range(3): sheet_source = workbook.sheet_by_name(sheet_name[j]) nrows = sheet_source.nrows for i in range(nrows): if is_Chinese(sheet_source.cell(i,0).value) == False and sheet_source.cell(i,0).value != "": a = (sheet_source.cell(i,0).value,sheet_source.cell(i,1).value) if a not in tup1 : tup1.append(a) else: pass else: pass #python弹出窗口,提示“读取完成!” msg.showinfo("Excel_Reading","读取已经完成!") #利用将元组转为字典,并统计各个区域的店铺数量 dict1 = {} for i in tup1: if i[0] not in dict1.keys(): dict1[i[0]] = 1 else: dict1[i[0]] += 1 return (dict1)
(二)写入部分
需要新建一个Excel,创建一个叫“总表”的sheet,写入标题、表头,以及根据上述的read_excel函数返回的字典,写入内容。
1、样式部分
因为写入函数.write()里面有多个参数是用来设定你写入内容的样式的,所以这里做一个函数,把需要设定的参数做一个封包。
def set_style(height,bold=False): style = xlwt.XFStyle() # 初始化样式 font = xlwt.Font() # 为样式创建字体 font.name = 'Times New Roman' font.bold = bold font.color_index = 4 font.height = height style.font = font alignment = xlwt.Alignment()# 为样式创建居中方式 alignment.horz = xlwt.Alignment.HORZ_CENTER style.alignment = alignment borders = xlwt.Borders() # 为样式创建边框 borders.left = xlwt.Borders.MEDIUM borders.right = xlwt.Borders.MEDIUM borders.top = xlwt.Borders.MEDIUM borders.bottom = xlwt.Borders.MEDIUM borders.left_colour = 0x40 # 边框上色 borders.right_colour = 0x40 borders.top_colour = 0x40 borders.bottom_colour = 0x40 style.borders = borders return style
2、写入excel
def write_excel(**dd): #两个**代表输入一个字典作为参数 f = xlwt.Workbook() #创建工作簿 ''' 创建第一个sheet: sheet1 ''' sheet1 = f.add_sheet(u'总表',cell_overwrite_ok=True) #创建sheet sheet1.col(1).width = 256 * 20 #调整列宽,256是一个固定的单位 row1 = [u'区域',u'店铺数量(家)'] #生成标题 sheet1.write_merge(0,0,0,1,u'总表',set_style(300,True)) #生成第二行表头 for i in range(0,len(row1)): sheet1.write(1,i,row1[i],set_style(220,True)) #写入数据 i = 2 for a,b in dd.items(): if b>=10: #将店铺数量大于10的数据,写入Excel sheet1.write(i,0,a,set_style(220)) sheet1.write(i,1,b,set_style(220)) i +=1 else: pass f.save('总表.xlsx') #保存文件,文件会保存在此Python脚本所在的文件夹内。
最后执行:
write_excel(**read_excel())
效果图:
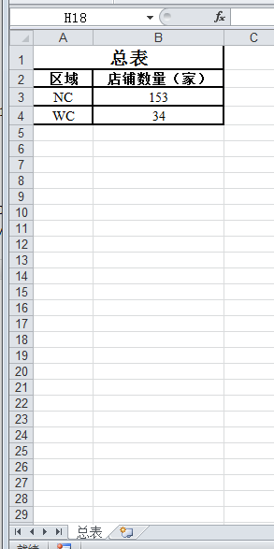
总结
应该说Python的xlrd、xlwt模块对于Excel的数据读取和写入非常简易方便。但是在使用xlwt时,存在一个问题,就是它无法直接对现有的Excel工作表进行写入,只能新开一个Excel。或者将现有Excel复制一个副本,另存为。
